If you’ve been following along last week, I wrote a tutorial on how to roll your own backups using a custom bash script. At the end of that article, you were essentially left with a script that squeezed your entire WordPress site into a tidy .zip archive, ready to store anywhere. Now it’s time to do just that!
Prerequisites
Rclone
Some kind of cloud storage (Google Drive, Dropbox, Backblaze, etc)
sudo privileges on your web host server
For this tutorial, we’re going to be using an incredible tool called Rclone. If you’ve been following along for a while, you’ll know this isn’t the first time I’ve referenced Rclone on my blog. A while back I wrote about using Rclone to mount web servers like a hard drive, and it’s really an amazing and versatile tool.
Setup
First thing’s first, we’ll need to make sure all your packages are up-to-date. I’m using an Ubuntu box, so it’s just a quick command, but if you’re on a different distro, use your appropriate package manager.
sudo apt update && sudo apt upgrade
With that out of the way, it’s time to install Rclone. Rclone has its own installation script which you can just pipe directly into bash. Just be aware, it’s not safe to pipe random scripts directly into bash (especially if you don’t know what the script is doing or where it’s from) but since Rclone is a trusted source, we can go ahead and run the install script provided in the official documentation.
If this doesn’t work for you, or if you’re running a different operating system, you can always check out the installation instructions in the official Rclone docs. https://rclone.org/install/
Once your installation is complete, you should be able to run man rclone and see the manual page for Rclone. If not, try reinstalling or try a different method if that didn’t work.
Connecting Your Cloud Storage
These steps will vary pretty wildly, depending on which storage provider you’re with and what they require in order to get set up with their platform. For this tutorial, I’m using Backblaze B2 bucket, but you can follow the dedicated configuration instructions for your cloud provider. Again, all of this information and more can be found in the Rclone docs.
The first step for everyone, regardless of provider, is actually starting the configuration process with the rclone config command.
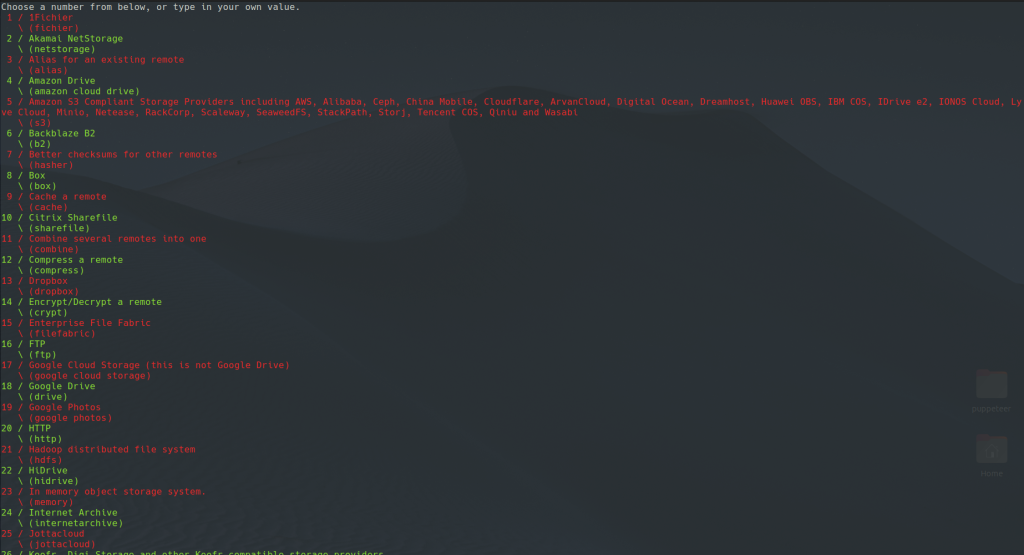
Once you’re in, you will be prompted to choose your cloud storage provider. As you can see, there are TONS of options.
Yes, it scrolls. In my case, since I’m setting up for Backblaze, I’m going to choose option 6, but again, you will choose whichever provider you like.
Next, you’ll be prompted to name your configuration. This is important to keep in mind, as we’ll be using this name in our command every time we want to interact with this cloud storage. That said, I like to keep my names as short and descriptive as possible to keep typing to a minimum and prevent typos from giving me grief.
Once my provider is selected, I will provide my account ID and then my application key. Once those two pieces of information are provided, I can then choose a handful of various options as to whether or not I want to be able to “hard delete” from this application, etc, etc, the default options are pretty good to use for all these questions.
A Note About The Rclone Command Format
At this point, you should be good to go! If you’ve configured your cloud storage correctly, now when you type rclone config you should see the name of the storage that you previously configured. Great work! At this point, now we’re ready to get familiar with a few of the basic Rclone commands and the way that Rclone works with Backblaze.
For our purposes, every part of the command will essentially stay the same except for the subcommand. There are a handful of subcommands you may find useful such as:
ls = List everything
lsd = List only the directories
delete = Delete everything in the following path
deletefile = Only delete this one specific file
copy = Copy everything in this path to the next provided path, skipping identical files
copyto = Copy just this one file
Awesome, Now What?
Now that you have Rclone installed and configured to be used with your favorite cloud storage solution, we’re ready to move that .zip archive off to be stored! To do this, we’ll be using the last subcommand as mentioned above.
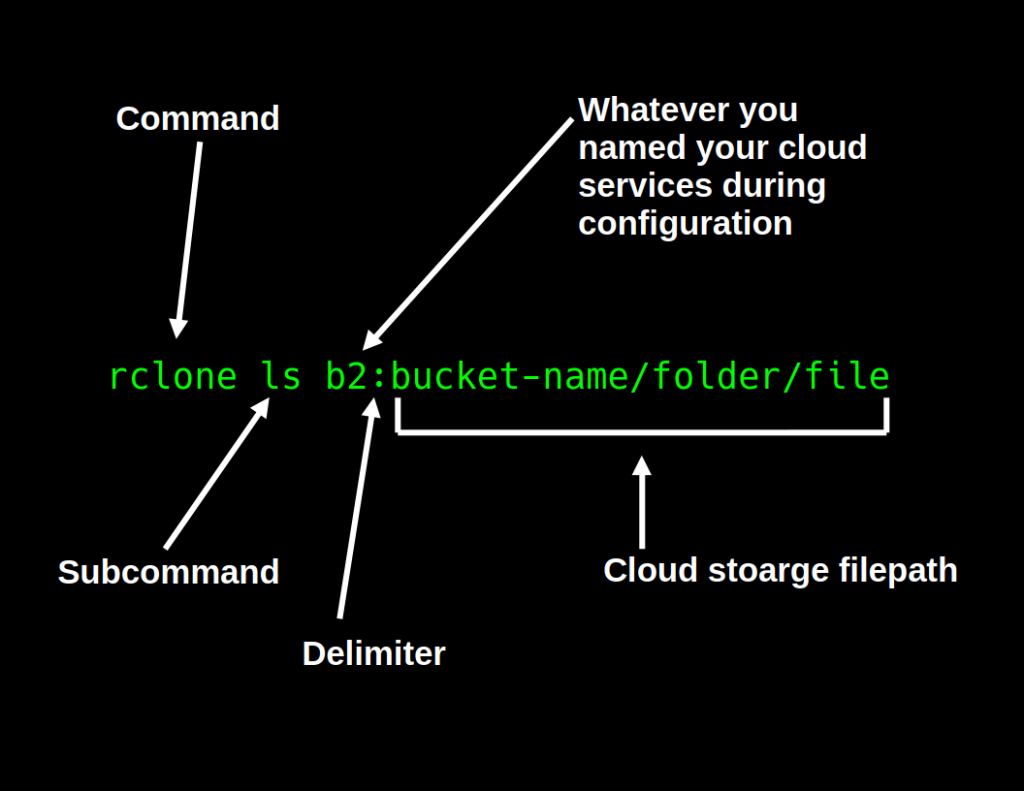
copy is a really cool in that you can use it to recursively copy large directories from one place to another (very useful), but in our specific case, if you were following the previous tutorial, we only need to copy a single .zip archive up to cloud storage for safe keeping. To do this, we’ll be using the copyto command. The format of the copyto command is like so:
For testing, if you’re just wanting to test your syntax and make sure you have everything correct before actually carrying out the copy command, you can append the --dry-run flag at the very end like this:
And that’s it! Another flag you can use for your own purposes, especially if the archive is pretty hefty, is the --verbose and --progress flags. These flags will give you more output and update you with various stats such as upload completed percentage, data transfer rates, and more. Again, just optional cool stuff to keep an eye on progress.
And That’s It!
Now you have everything you need to add the rclone command to your backup bash script. Now by executing a single file, you can roll up a copy of your website and ship it off to be stored for later! In the last part of this little blog series, we’ll go over exactly how to automate the execution of your backup script and how you can customize your very own running schedule so you can have backups make themselves whenever you want! Thanks for reading.
So you wanna roll your own backup solution, eh? Sure you could pay for some premium solution, but who are you kidding, they’re just copying files back and forth. How hard could it be? In this article, we’re going to take a look at writing our own backup solution. While technically, this solution can be molded to fit any type of website, app, or software, this particular script will be focused on making copies of and backing up WordPress sites. Let’s get into it!
Prerequisites
This tutorial assumes you already have root access to your hosting server, and will be performed pretty much exclusively from within a bash shell (hence the title). You will need a few things in order to get started:
SSH access to your host
Permissions to write and execute your own scripts
Permissions to install CLI tools on the server
Some place to store your backups (and access to that place)
With regards to that last bullet point, this can be virtually any cloud hosting service (Google Drive, Dropbox, Amazon, etc) or even a custom backup server.
Step 1
Once you’re all logged in and got your permissions all set up, you’re ready to go. Go ahead and create a new file with your favorite text editor (You can do this locally and upload it when you’re done, but I just wrote this directly on the server by using this command):
vim ~/backup.sh
Once you have your file opened, you can start off with a shebang, this tells the computer that this is a bash file and you should use bash to evaluate it:
#!/bin/bash
The first thing you’ll need is a place to temporarily store your backup files. Make sure you have permissions to access and write to this location, as you’ll be basing your entire backup out of this one folder. It can be anywhere, just so long as you can do stuff without permissions issues. For this example, we’ll be using /opt/backups/ but you can use any directory you like. Go ahead and make that backup directory if it doesn’t already exist:
mkdir -p /opt/backups/
Now that you have a temporary spot to keep the backup you’re about to create, let’s move into the root of the WordPress install so we can use wpcli to begin the process of making a backup. This can be located anywhere, but typically, WordPress installs are located in the /var/www/ directory, in a VPS or similar.
cd /var/www/example.com/
Next, using wpcli, we’ll export the entire database with the db export subcommand like so:
wp db export /opt/backups/backup.sql
This is just an example, but the premise of this command is to generate a sql file that you can use to recreate the existing SQL database on another empty database somewhere else. The final argument of this command simply provides a full filepath and filename for the resulting SQL dump.
Next, we need to make a copy of everything inside of /wp-content/ and save it in our backup directory. Luckily, we can copy the complete contents of the /wp-content/ folder over to our temporary backup directory and compress everything in-transit all in one single command:
tar -cvzf /opt/backups/wp-content.zip -C /var/www/example.com/wp-content/
If you’re familiar with the tar command, this should be pretty straightforward. If not, here’s a quick breakdown. tar is a LEGENDARY command. It’s the OG method for creating archives of virtually anything. From what I understand, it’s what the dinosaurs used to back up their blogs.
That’s right, tar is short for “Tape Archive”. I told you that’s what the dinosaurs used! After invoking the tar command, you can pass various options. The common options for creating an archive are cvf which stand for create, verbose file. Doing it this way would result in an archive ending in .tar but you can also pass the letter z as an option to format your archive into a more common .zip archive. You can also use tar to extract archives, but we’ll get into that later.
Let’s review Step 1 Because That Was A Lot
At this point, you should have lots of stuff in your bash file. It would probably be a great idea to save what you’ve got so far. First, we opened with a shebang and created our backup directory. Now, technically speaking, we would really only need to run the mkdir command once. So you could optionally exclude it from your script as long as you just create your backup folder once and have correct permissions for it, there’s really no need to keep creating a backup folder every single time you run this script in the future.
Next, we used wpcli to export the database and save it in our backup directory. There are other ways to go about generating an SQL dump file, you can do it from phpMyAdmin, or even from the SQL repl. By using wpcli, we’re simply exporting the database that we know for sure is being used by WordPress because just before it we used cd to change directories into the root folder of the WordPress install we’re trying to backup. wpcli uses the database credentials stored in wp-config.php to execute this command. And the final argument of the wpcli command saves the resulting SQL dump to our previously-created backup folder.
And finally, we used the tar command to create a .zip archive of everything inside the wp-content/ folder and save that in our backup folder as well. And ultimately, the idea is to create a single .zip archive that contains everything you need to start our website somewhere else. Knowing this, our folder structure is kind of awkward now. Our backup folder should look like this:
So yeah, technically, this is really all you need to completely restore a WordPress site, but you’ll notice it’s actually not including WordPress core and the all-important wp-config.php. So in order to restore this site, you’ll need to download WordPress core as well as set up an new database and wp-config.php file. This is quite a lot of stuff to tackle for when the time comes to actually restore the backup your taking.
Additionally, suppose a bit of time passes after you take your backup and the WordPress team releases a major core update, and now you find yourself needing to restore a backup. Doing things this way would require you to download the latest version of WordPress which could potentially cause issues with some of the items located in wp-content/plugins or even wp-content/themes.
Small Advantage of Doing Backups This Way
If you’re pretty infrequently restoring backups (if ever), the odds of you encountering a real problem with WP core updates disrupting a restore are pretty slim. Additionally, only targeting the wp-content/ folder for backups allows you to only back up the main content of your site without having to save core files every time you do a backup. However, admittedly, this is a very small space-saving tactic, and is ultimately your choice and one of the advantages of rolling your own backup script with bash! We get to decide what we keep and what we throw away (or don’t make copies of).
Disadvantage of Doing Backups This Way
I would be disingenuous to say that this is the method described above is the best way to go about this, because as mentioned before, you could run into some problems at restore time, as it’s unfortunately common that WP core updates have been known to break websites because plugin developers weren’t ready for this core update, their plugin depended on some feature of WP core, and that feature was removed at the time core was updated, and the result broke the website.
In order to avoid this situation, you can optionally (and at this point, I would probably just go ahead and recommend this way) include the core files in your backup. To do this, you need to modify your tar command and your wpcli command to look like this:
//SQL dump directly into the root of the WP install instead of putting it in the root of the backup folder
//if no arguments are passed after 'export', the default action is to generate an SQL file in the same directory where you are running the command.
wp db export
This will put your WP database into the root of your WP install with a default name and timestamp. Next, you’ll just zip your entire WordPress director (database included) and place it wherever you want and name it how you like. To put it in your user’s home directory, just run
tar -cvzf ~/site-backup.zip /var/www/example.com/
Additional Space-Saving Techniques
There’s another really cool feature of tar that we’re going to take advantage of in our script. It’s the -X option or --exclude-from option. If you’re familiar with Git, or have used version control before, you’ll likely be familiar with the .gitignore file. When using tar to create archives, you can using the -X option to essentially include your own ignore file to specify which files and folders you should exclude from your archive.
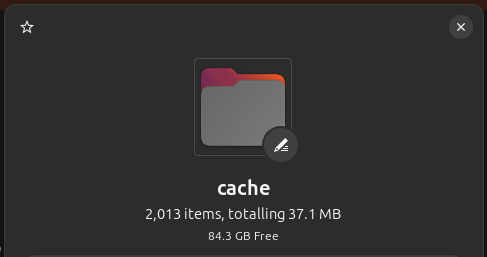
Why is this cool? Well, it’s common to find many WordPress installs using a caching plugin of some kind. This allows the server to save cached versions of various pages that visitors are requesting in improve overall site performance. For the purposes of creating a backup, there’s really no need to store this cache as part of our backup, especially since these cache folder can get quite large.
The above screenshot is just a small example of WP Fastest Cache running for a few weeks on a simple, low-traffic blog. Not much right now, but if you consider daily backups with even a max storage time of 10 days, this 37MB folder would quickly balloon to over 370MB across 10 daily archives, and that’s assuming the cache folder stays the same size for 10 days.
To exclude this folder (and others) we’ll need to create a small text file to tell tar which files and folder we’d like to exclude from our archive. You can name this file whatever you like, ignore.txt, exluded_files.txt, or even something more descriptive like cache_folders_for_tar_to_ignore.txt. But since you’ll be passing the name of this file to tar when you execute the command, the more concise, the better.
Inside the ignore file, let’s add a path to the cache folder we want to ignore. Keep in mind when defining file paths to exclude in tar, these file paths will need to be relative to the directory in which the tar command is being run. So for us, since we’ll be running tar from within the directory containing our WordPress install (/var/www/) we should have no problem.
inside /var/www/ingore.txt
wp-content/cache
With that added, suppose our WordPress site is located at /var/www/example.com and you’ve already exported your database.sql to the root of that install. To zip that entire site up, database and everything, but exclude the cache files located at /var/www/example.com/wp-content/cache/ you can run something like this:
cd /var/www/
tar -cvzf /opt/backups/example-backup.zip -X ignore.txt example.com
As tar evaluates this command, it’s going to take a look at /var/www/ignore.txt and know to ignore all our cache when creating this archive. Then it’s going to compress everything located at /var/www/example.com/ (except the cache folder) and copy it over to /opt/backups/example-backup.zip. Obviously, you can tweak this command to suit your own needs, but this exclusion feature of the tar command is very cool and pretty useful in our case!
Moving Your Archives Off-Server
Here’s the thing… Making regular backups of your site is pretty important. Lots of people use plugins to do this, and there’s lots of great plugins out there for doing just that. But here’s one of the biggest mistakes I see site owners do: They set that backups plugin to make routine backups… and they never move those archives off-server. Why? Simply put, lots of folks don’t put this much thought and energy into considering what a site backup is and does.
Unfortunately, I’ve come across many many WordPress sites that have a backup plugin, but it’s just saving tons and tons of backups to wp-content/ and the result is terrible. First, it’s not really making a “backup”. I mean, sure, it’s creating a copy of your website and creating an archive like we’ve been talking about… but it just stores it.. IN YOUR WEBSITE! So if your server goes down… so do all your backups!
The whole point of creating a backup archive like this is so we can move it off-server. There’s a metric ton of ways to do that, and we’ll get into that in my next post.
Okay, so for the uninitiated, there’s actually a ton of different ways you can interact with a linux terminal. Without getting too technical, there are things called “shells” and different shells, you can kinda think as different “flavors” or “styles” of using a terminal. Each of them with their own pros and cons, but if you’re just getting into this whole Linux shell thing, there’s a good chance you’ve come across one of the most widely-used shells out there called Bash. Bash stands for the “Bourne Again SHell” which has a very long and interesting history. Yeah, it’s probably older than you are.
Apart from Bash, there are other different shells like fish and zsh. For example, MacOS ships with zsh by default. After first being introduced to bash, a while back I decided to venture out into zsh and see what that could offer. And I liked it! It was primarily thanks to frameworks that enhance zsh like oh-my-zsh.
Oh My ZSH
At first, once I figured out how to install oh-my-zsh I primarily used it simply just to change the look of my terminal. Anything to just get away from the sort of “standard” default look of a regular bash shell. And as it turns out, there’s actually a TON of really cool ZSH themes available to try out simply by changing a single line in your ~/.zshrc file. (I actually used the jonathan theme for a really long time)
Many Years Later
I’m talking many. Seriously. That was literally the extent to which I used oh-my-zsh. Until just recently, I started discovering PLUGINS. The very first one I found use of was zsh-ssh and I still use this one daily for both work and personal. It’s incredible effective since sometimes my SSH config file can be several hundred lines long. The idea is simple. TAB to autocomplete your SSH alias. List all aliases from your config, search for the one you’re looking for using fzf. Incredibly useful, please check it out https://github.com/sunlei/zsh-ssh
And Finally…
I can’t believe I’ve gone so long without ever using or knowing about this one, but here ya go… autosuggestions for ZSH in general instead of just for SSH aliases. There’s a handful of ways you can configure it; I think by default it just goes by your bash (zsh) history, but so far, it’s amazing. It simply tries to fill in whatever command you’re about to type and so far it’s been amazing in saving me tons of keystrokes and freed up valuable brain space in remembering command syntax. Half the time I can never remember exactly which flag I need (or if I even need a specific flag) and all that mess. Autocomplete to the rescue!
Customization
By default, zsh-autosuggestions has you accepting the current suggestion with the right arrow key, which for me, is kinda clunky. One last tip and I’ll let you go. To change the key that’s used to accept the current autosuggestion, you can add the following one-liner to your ~/.zshrc file and you’ll be able to accept the current suggestion with TAB instead:
bindkey '^I' autosuggest-accept
Yeah, I know, ^I kinda looks exactly like CTRL+I, but trust me, it somehow translates to the TAB key. Go figure. Computers. If you need me, I’ll be autocompleting shell commands like I know what I’m doing! Thanks for reading.
What the heck is tmux? I gotta be honest, I didn’t really know or care what tmux was or what it could do until I came up against a problem I didn’t have a solution for. If you’ve been reading along, last week I dusted off my unused Raspberry Pi and hooked it up with an LCD display. Quite a fun project, and I’m definitely not done with it, but, it wasn’t too long after the LED display setup that I ran into a problem.
The Problem
You see, just to get started and learn my way around the LCD display, I ran a few scripts just to see if I could successfully display anything on the screen. It worked! As I got closer to my original plan for the Pi project, I wanted to be able to SSH into the Pi, write and execute a long-running script (long-running as in… basically forever) and then EXIT my SSH session and have the script still running. Yeah, as you can imagine, after exiting my SSH session, as soon as I was disconnected, my script would stop running as well. How can I solve this?
Enter TMUX
After a bit of searching, it would seem there are a handful of different solutions to this problem nohup, screen and of course tmux. I opted for tmux because I’d heard of it before but never really explored it, and lots of people online really seemed to use it with great satisfaction.
So what does it do?
tmux is a terminal multiplexer. Basically, it allows you to place a terminal inside your terminal and a terminal inside that terminal and so on. It’s extremely capable and very powerful, and for my particular use case, I’m barely scratching the surface. But the key feature I needed was tmux‘s ability to disconnect from and resume terminal sessions.
Setup
In order to use tmux, you’re gonna need it installed. Great news, it only needs to be installed on your server or the device you’re SSH-ing into. To install it, on Ubuntu/Debian, it’s as easy as sudo apt install tmux. If you’re using a different system, there’s tons of installation methods, and the whole project is on GitHub, so feel free to check it out
Basics
Once it’s installed, you can simply run it with tmux. It may not look like much happened, but once you see a little green bar appear at the bottom of your screen, that’s it. You’re IN. It’s just like a regular terminal session, you can do whatever you want (like execute long running scripts, ping google forever, count to a million, whatever). Once your terminal is going, you can detach from that session by hitting the default prefix hotkey CTRL+B (Kinda the Vim-equivalent of ESC, it won’t look like anything happened, but it puts you in “command mode” where tmux is essentially awaiting instructions).
After you’ve hit CTRL+B, you can detach from the active session with d. That’s it. Done. Now that you’re detached from your tmux session, you can exit the shell (disconnect from your SSH session) and that’s it. You’re free. Go for a walk, drive somewhere, go eat lunch, take a break, whatever.
Reconnecting
Then, some time later, let’s say you want to reconnect to that tmux session you started a while ago. Just SSH into that machine running your process (it can even been from a different device, location, or IP!) and you can reattach yourself to the last (most recently run) tmux session with tmux a which is short for tmux attach.
And boom. That’s it. You’ve reconnected to the terminal session you started some time earlier, you can kill the process, make updates, do whatever you need to do.
After moving from GalliumOS to Xubuntu, I noticed that playing YouTube videos on both Firefox and Chromium would result in decent playback for a few minutes, but suddenly the audio would turn into a solid beeping tone while the YouTube video displayed the white loading circle on top of the video as it continued trying to play.
The beeping sound would continue until I paused the video for long enough for the beep to stop on its own, or just close the tab. According to some forums around the net, it seemed to be an audio codec or driver issue. After a bit of digging through posts of similar but not exact audio issues, I found one that seemed to match my situation exactly.
The Solution
Apparently this was an issue with running a kernel that didn’t support and/or didn’t have a Sound Open Firmware (SOF) driver installed. Someone brought up an issue on their Github page and a solution was found and shared. This solution was also referenced in a few other places, so I gave it a shot and it 100% worked.
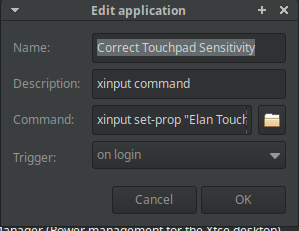
You can install the drivers with this epic bash script (please check it out before running it):
What are the values 1 1 1? This sets the sensitivity as close to the original ChromeOS as possible. Larger numbers will decrease sensitivity of various aspects. I never looked into which individual value represents.
I’ve really enjoyed using GalliumOS on my Chomebook for genuinely the last 5 years. It’s been an essential modification that has truly unlocked otherwise unattainable capabilities of my pint-sized little ‘puter. However, it looks as if the sun may be setting on this hardware, but it’s pretty hard to tell, as it could be user error or some other bloat that I’m unaware of.
The only thing I’ve grown concerned about is the fact that it appears that GalliumOS has lost support and/or interest and the project appears to have become abandoned. I tried a few other OS’s, and they just weren’t as good out-of-the box as GalliumOS. I love how they’d mapped out the keyboard to match just about every major function that was in the layout of the laptop keyboard.
Volume, brightness controls, all the F keys were functioning as expected right after install. So, as time has moved on, I started getting fewer and fewer updates to GalliumOS and so I gradually became more and more concerned about the security of the OS as a whole. As a result, I’ve started exploring alternatives to GalliumOS that had a larger audience and have kept up with all the ongoing updates.
Update Nov 4, 2023:
Make this adjustment permanent
In order to make these trackpad settings permanent, simply add the same command used above as a startup script:
This article assumes you’ve already got a Raspberry Pi set up and running the latest Raspberry Pi OS, and you’ll be hosting a React app locally (meaning it’s only accessible on your local network).
First you’ll want to enable SSH. There’s some fancy ways to do this in the terminal, but the easiest is to just enable it in the preferences.
Once you’ve got SSH enabled, there’s one little security doodad you’ll need to fix. You’ll want to open your Pi’s terminal and head over to your config file and edit it with nano: sudo nano /etc/ssh/sshd_config. You potentially won’t need to run this command with sudo, but when you do… you’ll most certainly feel more powerful.
Once you’re inside, you’ll want to be on the lookout for a line that reads: #PermitRootLogin prohibit-password Once you find that line, you’ll want to edit it so it reads like so: #PermitRootLogin no That’s it! You can close out of nano and save your changes.
Next, you’ll want to confirm which IP address your Pi is using on your local network. Do find this, just type hostname -I.
UPDATE: Alternatively, an even simpler way to output your PI is literally just ip address. I’m never gonna remember that.
At this point, you’re pretty much home-free. Hop onto a different computer on your local network and open a terminal. I’m assuming you’ll be ssh-ing from another Mac or Linux machine. Go ahead and SSH into your pi with ssh [username]@[IPaddress] at which point, you’ll be prompted for the password on the Pi to log in. Enter the password and you’ll hit the /home directory of the Pi!
Now, you can just build out your React app like you would normally, in my case I just installed Node, ran npx create-react-app /some-project and off it went! Once your React app is set up, you can access it from any device on your network by going to the IP address of your Pi (the one that appeared when you ran hostname -I), then a colon with the port number, just like you would on localhost.
Setup rclone using rclone config then use the mount command rclone mount remote:bucket/folder/file
The Long Answer Mixed With Personal Experience:
This is a little bit embarrassing, but I’ve been using Backblaze for years at this point and I’ve only mounted my first B2 bucket just now. I have no idea why it’s taken me so long, and I just sort of stumbled across the solution as I was making manual backups to some folders and my mind was blown.
As you may (or may not) already know, Backblaze B2 has a somewhat limited number of options when it comes to interfacing with your files on Linux. At the time of this writing, Backblaze lists just 3 options for essentially using their B2 service on Linux. I’ve only tried Rclone, and over the last few years it’s been fine.
After taking a few minutes to familiarize myself with the docs, I was able to easily set up my B2 bucket. Once I had it set up, I used it as an extremely simple way to just upload large files. It should be noted that also, at the time of this writing, B2’s web interface limits uploads to around 200MB. Anything larger requires you to connect to the server directly via some supported application.
At the beginning, I was just excited to get something to work. After setting up my B2 bucket, I was able to upload and download files and folders using the [bash]rclone copy[/bash] command. And that worked for a bit. Then one day I ran into an issue where I was looking for a specific photo I’d backed up. I knew I’d backed it up, but I didn’t have a way to really search for it especially since it was named something like IMG_0023523.jpg or whatever. And technically, yes, you can preview image files on their web interface, but it is wildly impractical. So that was the first issue I ran into with my limited knowledge of Rclone.
At the time, I also didn’t have a practical way of automating backups to run in the background. It was just up to me to decided whenever I had time to figure out which folders I wanted to backup and figure out where I wanted to save them by either memorizing the exact file path on the B2 bucket, or finding it using rclone lsd remote:bucket to list all directories in a given filepath. Still not very usable or practical. So far, it had been working for folder manual backups and for client file deliveries.
However, just this week, I ran into some issues with my computer which caused the POST to fail, so when I hit the power button to boot up, the lights would come on, and the fans would start spinning, but the screen just stayed black. Absolutely scary considering my terrible backup solution. Ended up fixing the issue and got the machine to boot, but now I’m taking this opportunity to back up everything.
So of course, I went at it using the only way I knew at the time: rclone copy path/to/local/folder/ remote:bucket/folder. And off it went. It’s a sizable backup, and it will take a while, and that’s fine. I was looking around Backblaze’s newly redesigned site and I don’t even know how or what I was looking for, but I came across this mysterious rclone mount command. My mind is will be forever blown and all my issues of previewing image files and scheduling backups will now be a distant memory.
Once you’ve set up and configured Rclone, you’ll need to create an empty folder to mount your B2 bucket inside of. I’ve already got several internal storage drives mounted at /mnt/. Yours may be mounted elsewhere, but I think that’s a pretty standard mount location. Once you’ve created your folder, you’ll want to confirm it has the correct permissions to work with rclone mount.
[bash]sudo mkdir /mnt/MyB2MountPoint[/bash] and then [bash]ls -l /mnt/[/bash]. The -l flag will display all the read/write/execute permissions as well as ownership of the files and folders targeted with ls. If you created your mountpoint folder using sudo like I did, there’s a hot chance that owner of your newly created mount directory will be root. Depending on how you’ve set up your permissions, this may or may not work. In my case, it didn’t.
To fix this, I simply changed folder ownership to my username. chown username /mnt/MyB2MountPoint. After I’d done that, I was able to run rclone mount remote:bucket/folder /mnt/MyB2MountPoint. Just keep in mind, this command was run in the foreground (running in the foreground is the default) which means as soon as that terminal window is closed, or the program is killed with CTRL+C or receiving a SIGINT or SIGTERM signal, the mount should be automatically stopped.
If you prefer, you can mount your B2 drive in the background with rclone mount remote:bucket/folder /mnt/MyB2MountPoint --daemon. If you do this, in order to unmount, you’ll have to do so manually using fusermount -u /path/to/local/mount.
It wasn’t too long ago I uploaded a post on how I built out the Raspberry Pi 4 for the Light Quest arcade project. It was all promising at first, until I did my first test. I figured, before I go down the long, long road of fully developing an entire game from scratch, going through countless revisions (hopefully not countless) and finally getting to the point where I’m ready to deliver the game to run it on the Raspberry Pi, only to find out the game wasn’t compatible with the Pi hardware… It’d be best to just run a simple test first with a game I already had lying around. Yes, I got the controls working for the game, but that was only on my laptop. I wasn’t satisfied until I had a game that I’d written fully functional and running smoothly on the Pi.
Good news: I ran this check early. Bad news: The test unearthed some unfortunate results. Something that I didn’t completely realize until after the Pi was ordered and assembled and set up with a fresh copy of Raspian, was the fact that Pi’s run ARM CPU architecture. This is great except when you need X86 architecture. The executible Linux binary I had exported for Pi was only compatible and compiled for x86 architecture. When I executed on Pi, it just threw an error and that was that. There was no running the game unless I could export for ARM. After many-a internet searches, almost zero game engines support ARM architecture. I say almost because there were a few examples of crazy experimental setups running Unreal or Unity on ARM boards, but it wasn’t exactly straighforward. Keyword: “experimental”.
So finally, I came to terms with the fact that it would just be easier to swap hardware in favor of an X86 CPU board instead of forcing the Pi to do what I needed it to do. So after a quick call to IT, they just happen to have a few chromeboxes lying around that were being replaced. Score! I was able to snag one of the boxes for the arcade project. The new gameplan was to wipe the chromebox, install GalliumOS, and test the linux executable on that box. But first, the GalliumOS install. Luckily I have some previous experience with GalliumOS and have installed it on 2 laptops before.
The first step is finding the four corner screws that keep the main case assembly together. They can easily be located by popping off the rubber feet at the bottom of the chromebox with a small flathead screwdriver or a knife. With those screws exposed, you can pull them out with a Phillips head screwdriver.
With the four corner screws removed, the top of the case can easily slide off. With the chromebox top removed, you can get a good look at the internal components. Upon careful inspection and a little bit of help from Mr. Chromebox, I was able to find the write-protect screw. Yes, there is a physical screw that protects custom firmware from being written without removing this screw. I guess Google doesn’t want anyone to accidentally boot a different operating system.
Once the write protect screw is removed, I was able to close everything back up and boot into GalliumOS without having to hit CTRL+L every single time to make sure that it boots into legacy mode. And with a few settings tweaked, I now have a chromebox that automatically logs in as admin at boot and launches the Linux binary executable that I was testing on the Raspberry Pi 4 that was failing previously. Problem solved.
After watching several videos on the topic of pixel art, researching some of the artists in the top of my search results, I decided to make the leap and change up my graphics creation strategy. For me, personally, it took quite a bit of time to figure out how to compile the software from scratch (because I had to compile some of the dependencies as well), but without further ado, here we go.
Step 0.0: CMake
I started off like normal, I guess, cloned the repo, and got to work inspecting the files, README, INSTALL, etc. I went through the process for several minutes only to find out that my version of CMake (installed like sudo apt install cmake was several versions behind the minimum requirement. I ran cmake --version only to find out that I was running version 3.10 when the minimum requirement is 3.14. So if you already have CMake 3.14 or above, you can skip this step. Otherwise, here’s how you update.
First off, you’ll want to get rid of any old versions of cmake by running sudo apt remove cmake. After that, head over to https://cmake.org/download/ to grab yourself an updated copy of cmake. I ended up downloading the source code and building from scratch, but that’s not completely necessary because there are several pre-built binaries available as well.
Step 0.1: Clone that Repo
This one’s pretty straightforward. Just make sure you have git installed and run git clone --recursive https://github.com/aseprite/aseprite.git
The next step is getting all of the tools required to build Aseprite. This can be found in INSTALL.md
Step 0.2: Get your tools
This is the very first step in INSTALL.md. There are step-by-step instructions inside that pertain to every operating system. Just be sure to read them carefully! This is the part where you install cmake, but just be extra sure to check your version by running cmake --version. If you don’t have version 3.14 or higher, refer to step 0.0.
Just to reiterate, the command to install all your dependencies in one go is sudo apt-get install -y g++ cmake ninja-build libx11-dev libxcursor-dev libxi-dev libgl1-mesa-dev libfontconfig1-dev again, just make sure to double check your version of cmake.
Step 0.3: Make sure you have Skia
This one was a little tricky because this dependency wasn’t actually covered in the dependencies install command from step 0.2. It very well may be because Skia is actually a graphics library made available by Google, and thus, not available on traditional linux repositories. More information on the Skia project can be found at skia.org.
Inside the INSTALL.md file that you got when you cloned the aseprite repository, there are some notes regarding the moment you run cmake. You have to run it from inside the build/ directory (which you’ll need to create), and you will need to define where you have either compiled or decompressed your copy of Skia. The example directory (the default defined in the provided cmake command) is $HOME/deps/skia/ or something similar.
You can either compile skia yourself using the step-by-step guide provided by the team at Google, or, conveniently enough, the team behind Aseprite has a precompiled binary just for you! All you have to do is drop it in your $HOME/deps folder and continue with the steps to compile. Aseprite’s precompiled binary of skia can be found at https://github.com/aseprite/skia.
Step 0.4: Run CMake
Once you’re done cloning the repository, you’ll want to go inside it with cd aseprite. Next you need to create a folder to build your files inside of, since builds inside the source aren’t allowed. mkdir build && cd build/.
The basic syntax of cmake is cmake [path/to/source/containing/CMakeLists.txt] [OPTIONS]. So from inside your build directory, you’ll need to define the source (one folder up). Then from there, you’ll need to tell cmake where your skia files are. More information on this can be found in the INSTALL.md file
Almost there! Once you’ve build all the files using cmake, and you didn’t encounter any errors, congrats! You’re almost there! If there are any more errors to come (in my experience) they’ll be on this very last step. The last command in INSTALL.md is ninja aseprite. That will actually start the build process and end up spitting out an executable binary that you can launch once everything is finished running.